MML - Review for Exam 4
We will have our fourth exam next Wednesday, April 23. This review sheet is again meant to help you succeed on that exam.
What is the sigmoid function \(\sigma(x)\)? More specifically,
- Write down the exact algebraic definition of \(\sigma(x)\).
- Draw a graph of \(\sigma(x)\).
- In the context of binary classification, how do we interpret the sigmoid?
- Show that \(\sigma(x)\) satisfies the equation \(\sigma' = \sigma(1-\sigma)\).
- Suppose that the number \(x_0\) is chosen so that \(\sigma(x_0) = 0.8\). Compute \(\sigma'(x_0)\).
What is the ReLU function \(\text{ReLU}(x)\)? More specifically,
- Write down the exact algebraic definition of \(\text{ReLU}(x)\).
- Draw a graph of \(\text{ReLU}(x)\).
- Suppose that the number \(x_0\) is chosen so that \(\text{ReLU}(x) = 0.8\). Compute \(\text{ReLU}'(x)\).
Let’s suppose that \(x\) and \(y\) represent two vectors of purely categorical data. Let’s say
\[\begin{aligned} x &= [\text{red}, \text{yel}, \text{blu}, \text{blu}, \text{yel}, \text{yel}] \\ y &= [\text{blu}, \text{yel}, \text{red}, \text{blu}, \text{yel}, \text{yel}]. \end{aligned}\]
How do you compute the Hamming distance between these two vectors and what is the value?
Consider the categorical data vector \[[\text{red}, \text{yel}],\] where the set of all possible values for the each entry is red, yel, and blu. Write down the one-hot encoding of that data vector.
Consider the vectors of mixed type
\[\begin{aligned} x &= [\text{red}, \text{yel}, 8, 4] \\ y &= [\text{blu}, \text{yel}, 2, 7]. \end{aligned}\]
Let’s suppose that the numerical variable can take values from 0 to 10.
- What is the standard Gower distance between these vectors?
- Why might we like to use the Gower distance in K Nearest Neighbor algorithms?
Draw an expression graph for \[f(x_1, x_2) = x_1^2 e^{-(x_1^2 + 2 x_2^2)}.\] Be sure to reuse node values as necessary.
Compute the convolution of the data \(D\) with the kernel \(K\) given by
| \(D=\,\) | 1 | 1 | 2 | 2 | 3 | 3 |
and
| \(K=\,\) | 2 | 0 | 2 | . |
Consider the two two-dimensional kernels \[ K_1 = \begin{bmatrix}1&1&1\\1&-8&1\\1&1&1\end{bmatrix} \quad \text{ and } \quad K_2 = \begin{bmatrix}1&1&1&1&1\\1&1&1&1&1\\1&1&-24&1&1\\1&1&1&1&1\\1&1&1&1&1\end{bmatrix}. \]
- Could these be appropriate for edge detection in image processing? Why or why not?
- What kind of difference might you expect in the behavior of these?
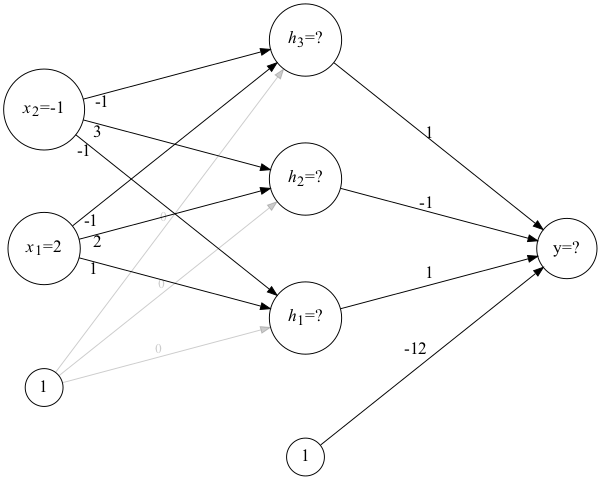
The neural network shown in figure 1 below consists of three layers:
- the input layer,
- one hidden layer, and
- the output layer.
Let’s also suppose that the input layer has a ReLU activation and the output layer has a sigmoid activation.
Note that the inputs are given. Use those inputs together with forward propagation to compute the value produced by this neural network.