Normal Models¶

The theoretical foundation of inference is to model our data with some distribution. By far the most common such distribution that arises in practice is the normal distribution.
Normal curves¶
The standard normal¶
The standard normal distribution is a specific bell shaped curve; its graph is shown at the top of the page above. It has a maximum as it crosses the $y$-axis; its mean is zero. It decreases as we move away from the mean and tapers off to the $x$-axis. It's scaled so that the total area under its graph is one. The area under the curve is distributed in a specific way; it's standard deviation is one.
More normals¶
The standard normal is one of a specific family of bell shaped curves. We can change the mean by shifting the graph to the left or to the right. We can change the standard deviation by compressing or dilating along the $x$-axis while simultaneously doing the opposite along the $y$-axes. Several such curves are shown in the figure below.

Note that the mean and standard deviation are denoted $m$ and $s$ in the figure above. Often, we denote these with the Greek letters $\mu$ and $\sigma$.
A formula¶
It's worth mentioning that there is a specific formula that generates the normal curves, namely $$f_{\mu,\sigma}(x) = \frac{1}{\sqrt{2\pi}\sigma} e^{-(x-\mu)^2/(2\sigma^2)}.$$
You can explore the graphs of these functions on Desmos.
Modeling histograms with normal curves¶
Often, if we scale a histogram so that the total area of its rectangles is one, then the normal curve with the same mean and standard deviation will match the histogram fairly closely. An example is shown below.

We've got a dynamic illustration on our webpage.
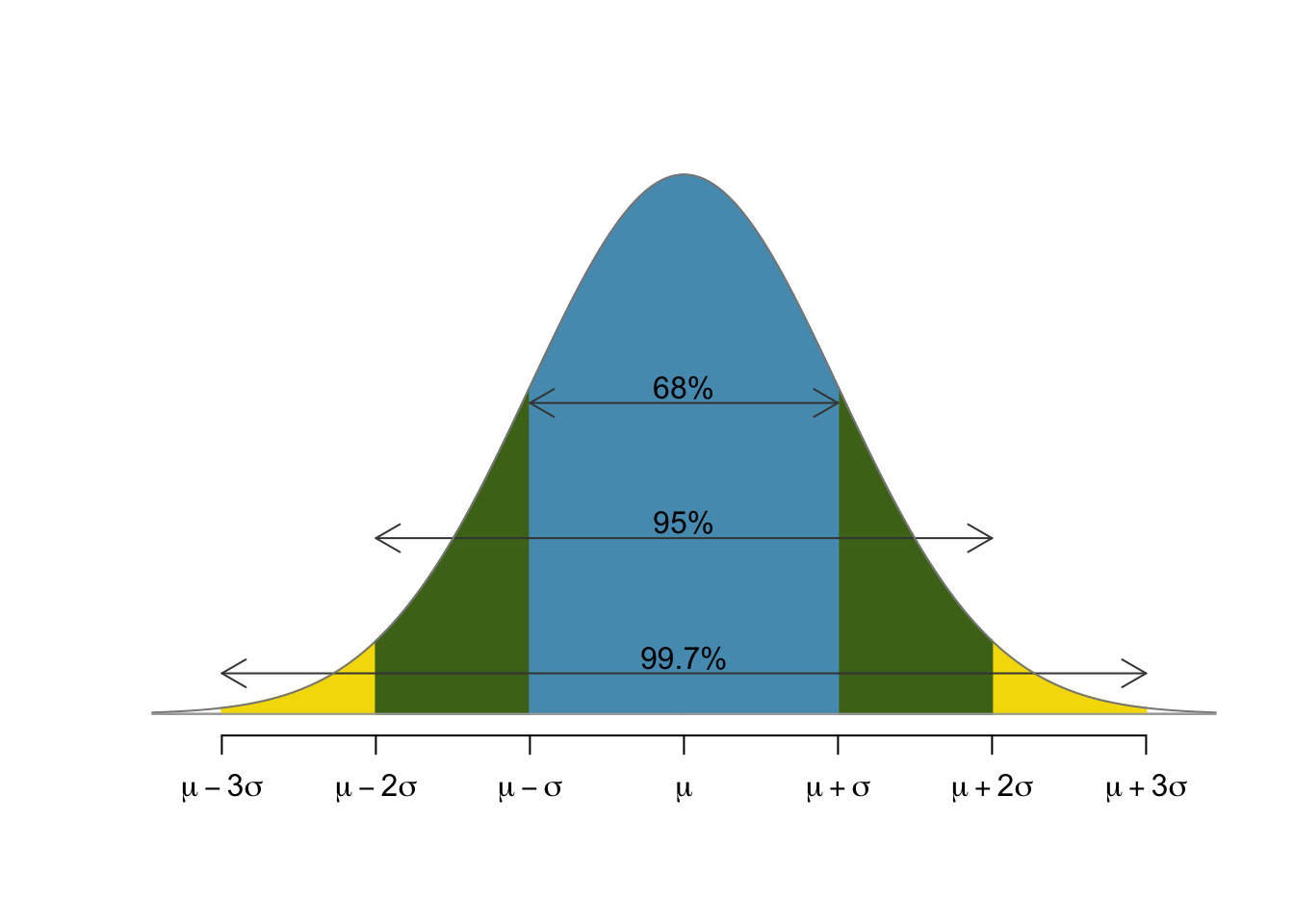
The 68-95-99.7 rule¶
There is a statistical rule of thumb called the 68-95-99.7 rule that states that
- 68% of the population lies within 1 standard deviation of the mean,
- 95% of the population lies within 2 standard deviations of the mean, and
- 99.7% of the population lies within 3 standard deviations of the mean.
For this to work, the property being measured should be normally distributed. If so, then the rule of thumb follows from the fact that this property holds for the standard normal:
Example¶
Let's suppose that the mean life expectancy of a cat is 14 years with a standard deviation of 2.5 years. Assuming that the cats' life spans are normally distributed, is it reasonable to expect a cat to live to 22 years old?
Solution: Well, the $z$-score for a 22 year old kitty cat would be $$Z = \frac{22-14}{2.5} = 3.2.$$ As we know, only $0.3\%$ of cats live beyond a $z$-score of 3, so a 22 year old cat would be quite rare indeed.
Standard deviation as a ruler¶
The mean and standard deviation can be used to standardize data. A principle tool to do so is the $z$-score.
The heptathlon¶
I've got a CSV on my website that contains the results of the 2008 Olympic Heptathlon. Here are the first few rows:
import pandas as pd
df = pd.read_csv('https://marksmath.org/data/heptathlon.csv')
df.head()
As it turns out, Nataliia Dobrynska won the long jump by about half a meter over the average jump; Hyleas Fountain won the 200m by a second and a half faster than the mean. Which of these two results deserves more points?
One way to compare these results involving different units is to use the standard deviation as a ruler. To do so, we standardize. Given a data point $X$ chosen from data that is normally distributed with mean $\mu$ and standard deviation $\sigma$ we compute $$Z = \frac{x-\mu}{\sigma}.$$ With this choice of $Z$, note that $$X = \mu + Z\sigma.$$ Thus, $Z$ measures exactly how many standard deviations $X$ is from the mean. This computation is sometimes called the $Z$-score.
Here's how we apply this to the 200m vs long jump question:
two_hundred_x = df.two_hundred.min()
two_hundred_mean = df.two_hundred.mean()
two_hundred_std = df.two_hundred.std()
(two_hundred_x-two_hundred_mean)/two_hundred_std
long_jump_x = df.long_jump.max()
long_jump_mean = df.long_jump.mean()
long_jump_std = df.long_jump.std()
(long_jump_x-long_jump_mean)/long_jump_std
It looks like the long jump is the more impressive result.
SAT Example¶
The SAT is designed to have mean score of 500 with a standard deviation of 100. Let's suppose you score a 650.
a. What is your $z$-score? b. What is your percentile, according to the normal model?
Solution: For part (a), the $z$-score is simply $$Z = \frac{650-500}{100} = 1.5.$$ We can answer part (b) by computing an area under the standard normal curve as shown below:

This type of area is typically computed using either software or a table. We will learn how to do this in Python soon but, for now, let's take a look at this table.
Assessing normality¶
In the previous problem, we assumed that the lifespan of cats was normally distributed. Is this a valid assumption? I have no idea, but given a data set there are ways to check.
A histogram¶
Human heights are classically known to be normal. Let's take a look at the heights of the over 9500 men chosen from our CDC data set.
import pandas as pd
df = pd.read_csv('https://www.marksmath.org/data/cdc.csv')
df.height.hist(bins = 20, grid=False, edgecolor='black');

Looks kinda normal.
The normal probability plot¶
There's a more sensitive tool, though: the normal probability plot - more generally called a quantile-quantile plot.
Here’s the basic idea: Suppose we have some sample data consisting of $n$ numerical values. We’ll make a plot with $n$ points - one point for each of the $n$ values. The vertical component for a given data point is just the value of the data point itself. The horizontal component for that given data point is determined by the $z$-score of that percentile.
For example, $z=1$ is greater than about 84% of all values produced by the normal distribution. You can look that up in a normal table or use the following Python command:
from scipy.stats import norm
norm.cdf(1)
Furthermore, the $84^{\text{th}}$ quantile for the men's CDC height data is 72 inches, as the following computation reveals:
df.height.quantile(0.84)
Thus, the point $(1,72)$ should be on the normal probability plot for this data. Here's the normal probability plot of that height data, together with the point $(1,72)$ shown in yellow.

By contrast, income is classically not normally distributed. Here's a normal probability plot for a random sample of incomes taken from the US census:
