Intro to Hypothesis Testing¶
The general idea¶
Often in statistics, we want to answer a simple yes or no question.
- Is my candidate going to win an election?
- Does this drug alleviate symptoms?
- Does a new teaching technique improve student learning outcomes?
The idea behind hypothesis testing is to
1) Clearly state the question we are trying to answer in terms of two competing hypotheses and 2) Assess the likelihood of the two hypotheses in light of data that's been collected.
Statement of the hypotheses¶
The two competing statements in a hypothesis test are typically called the null hypothesis and the alternative hypothesis.
- The null hypotheses $H_0$ is a sentence representing a skeptical perspective or status quo
- The alternative hypotheses $H_A$ represents an alternative claim under consideration
The $p$-value¶
In the context of hypothesis testing, the $p$-value represents the probability of generating observed data as least as favorable to the alternative hypothesis under the assumption of the null hypothesis. A small $p$-value is evidence agains the null hypothesis.
Seems a little confusing - perhaps, an example would help?!
The first example - historically¶
The first known use of what we now call a $p$-value is typically credited to John Arbuthnot in 1710. He was interested in the following question:
Are males and females born at equal ratios?
To address this question, he examined birth records in London for each of the 82 years from 1629 to 1710. In every one of those years, the number of males born in London exceeded the number of females. Under the assumption that males and females born at equal ratios, we'd expect that there would be more women about half the time. So it would be quite unlikely that there would be more men every year.
To be more precise on what quite unlikely means, Arbuthnot argued as follows: The probability that more males are born in any particular year is $1/2$. Thus, the probability that more males were born each one of the 82 years from 1629 to 1710 would be $$\frac{1}{2} \times \frac{1}{2} \times \cdots \times \frac{1}{2} = \left(\frac{1}{2}\right)^{82} \approx 2.06795 \times 10^{-25}.$$ Given the riculously small probability that the observed data (82 years of more males) could have arisen under the under the assumption of equal ratios, it seems reasonable to conclude that the assumption was incorrect in the first place.
The modern formulation¶
Recall the first two steps in modern hypothesis testing: Statement of the hypotheses (null and alternative) and computation of the $p$-value. For Arbuthnot's problem, the question concerns the ratio $r$ of male births to female births. Stated in terms of $r$, the hypotheses are:
- $H_0$: $r=0.5$
- $H_A$: $r \neq 0.5$.
Prior to computing the $p$-value, the researcher typically specifies a desired confidence level $\alpha$. Common choices might be $\alpha=0.05$ for a $95\%$ level of confidence or $\alpha = 0.01$ for a $99\%$ level of confidence or something even closer to $100\%$. If the computed $p$-value is then less than $\alpha$, then we say that we reject the null hypothesis.
If we specify $\alpha=0.01$ for a $99\%$ level of confidence in Arbuthnot's question, the computation of the $p$ value is $(1/2)^{82}$, which is much smaller than $0.01$. Thus we reject the null.
Ultimately the conclusion of a hypothesis test is always either:
- We reject the null hypothesis or
- We fail to reject the null hypothsis.
Note this strange double negative language - we never actually say that we accept the null hypothesis. The null hypothesis is the already the status quo; it doesn't need acceptance.
A normal example¶
In applied statistics, the computation of a $p$-value is typically done by modeling the data with a distribution - often, a normal distribution. Let's try this with a basic example.
According to Google, the average height of men is 69.3 inches. Let's examine this hypothesis using a sample chosen from our CDC data set. I suppose we'd be surprised if we could reject this hypothesis so let's shoot for a $99\%$ level of confidence.
Let's carefully formulate our hypotheses. If $\mu$ represents the average height of men, then:
- $H_0$: $\mu=69.3$
- $H_A$: $\mu \neq 69.3$.
Now, let's collect some data to examine these hypotheses - again, at a $99\%$ level of confidence.
Here's a random sample of 100 men chosen from our CDC data set with the corresponding mean and standard error:
import pandas as pd
import numpy as np
from numpy.random import seed
from scipy.stats import norm
df = pd.read_csv('https://www.marksmath.org/data/cdc.csv')
seed(1)
df_men = df[df.gender == 'm']
samp = df_men.sample(100)
samp.head()
Now, here are the mean ans standard error associated with this sample:
m = samp.height.mean()
se = samp.height.std()/np.sqrt(100)
[m,se]
The mean computed from the data is about $70.14$, which is not 69.3 but it differs by just less than an inch. Is this sufficient to reject the null hypothesis that the mean is actually $69.3$?
To examine this question, we compute the probability that we could get that computed mean or worse under the assumption of the null hypothesis. Put another way, we need to find the shaded area below where the normal curve has mean $69.3$ and standard deviation $0.3213$ a dictated by the problem.
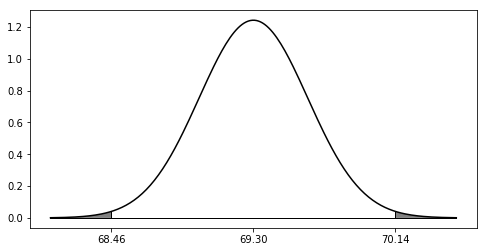
This area can be computed by looking the appropriate $Z$-score up in a table, or it can be computed on the computer:
test_stat = (m - 69.3)/se
test_stat
2*norm.cdf(-test_stat)
At a 99\% confidence level, I guess we reject the null!
The $t$-test via ttest_1samp¶
Like any good statistical package, the scipy.stats module has functionality that automates hypothesis testing - namely the ttest_1samp command:
from scipy.stats import ttest_1samp, t
ttest_1samp(samp.height, 69.3)
Note that we've generated the exact same test statistic - but, we've got a slightly different $p$-value. In fact, this $p$-value is just on the other side of the threshold so that we fail to reject the null! What's the deal?
Well, the $t$-test, as the name suggests uses the $t$-distribution and, even though the sample size is 100, there's still a little difference. Here's how to compute the $p$-value using the $t$-distribution directly:
2*t.cdf(-test_stat,99)
Two sides of the alternative hypothesis¶
When written symbolically, the null hypothesis is typically an equality like:
- $\mu =$ some value.
The alternative hypothesis is typically an inequality which may take one of several forms:
- $\mu \neq$ some value,
- $\mu <$ some value, or
- $\mu >$ some value.
The previous example is two-sided since the null has the form $\mu \neq$ some value. The latter two are one-sided hypotheses.
Example¶
Conventional wisdom states that normal human body temperature is $98.6^{\circ}$ but, according to a 1992 research paper entitled "A Critical Appraisal of 98.6 Degrees F" that appeared in The Journal of the American Medical Association, it's actually lower. I've got the data from the research paper on my webspace so that we can grab like so:
df = pd.read_csv('https://www.marksmath.org/data/normtemp.csv')
df.head()
For the current discussion, we are interested in the body_temperature variable.
temps = df.body_temperature
m = temps.mean()
s = temps.std()
n = len(temps)
[m,s,n]
So it looks like there were 130 folks in the study with an average temperature of $98.249^{\circ}$ and a standard deviation of $0.733^{\circ}$. The average temperature from this sample is indeed lower than $98.6$, but let's use a one-sided hypothesis test to examine whether this is genuine evidence against the conventional wisdom. To be clear, our hypothesis test looks like so:
- $H_0$: $\mu=98.6$
- $H_A$: $\mu < 98.6$.
Let's use a confidence level of $99\%$.
Well, the standard error is $$SE = \frac{\sigma}{\sqrt{n}} = \frac{0.7331832}{\sqrt{130}} = 0.0642884.$$
Thus, our $Z$-score is $$Z = \frac{\bar{x}-\mu}{SE} = \frac{98.249 - 98.6}{0.0642884} = -5.45977.$$
This is literally off our table so our one-sided $p$-value must surely be much less than $0.01$; thus, we reject the null-hypothesis.